
An interesting question to which I'd be inclined atm to answer in the negative - more detail below...DCHindley wrote: ↑Sat Sep 30, 2023 5:11 amI can tell you are a relational database developer.Leucius Charinus wrote: ↑Sat Sep 30, 2023 4:16 am There is little agreement on what the puzzle is. The way I see it is like a four dimensional jigsaw puzzle where the pieces represent historical evidence set into a chronological framework. Some of the evidence has been fabricated.
...
Here is a chronological map of this evidence:
https://www.academia.edu/78665273/Evide ... Literature
Am curious if it is possible to reduce the data to 2nd, 3rd or even 4th normal form?
Our modern databases are designed (especially in a business applications) within an environment where we have oodles of data which is generally as up to date as possible. Processes are normally included which update the data and where certain (especially critical) elements of the data are missing then usually great effort is expended to research this and the data is meticulously gathered.Years ago, I dabbled with Clarion Database Developer, Paradox and MS Access (still have them, although the versions I have no longer run under the newer versions of Windows, except Access which MS updates constantly so your version is always out of date), and routinely organize payroll information in spreadsheets (which are really databases).
For spreadsheets I use some of the Excel functions to work with the data, and while I can bring out the info I need to know (was a reported Payroll amount correctly calculated, we employ codified rules in Workers' Comp insurance circles), but I have to admit my approach is not focused. Doesn't help that the tools we are supplied are about 20 years out of date, but we are all supposed to follow those rules, however badly written with run on sentences, inconsistent formats for definitions, all sorts of oddities.
This is not an option for a database designed to reflect ancient history. Most of the data is irretrievably lost to us and may never be found. As a result any such database is bound to contain oodles and oodles of NULLS. That is, unknowns. This will apply to most of the key and fundamental fields. This is a massive problem when one attempts to interrogate the data with a query language such as SQL.
So Dave my answer atm would be an historical database (especially for ancient history, modern history may be less problematic) cannot be subjected to normalisation processes. Or rather, the normalisation process would not be able to overcome the massive data integrity issues which arise because of NULLS in the data. You could try and normalise it however I'd reckon you'd still be left with massive data integrity problems such that not much could be gained. It would reflect the GIGO principle.Can historical data be subjected to normalization? These two things may be like apples & oranges, different fruits completely.
Dave
Here's an example:
HISTORICAL IDENTITIES
As a starting point we could nominally script into the database most of the Roman emperors because of their coins and other evidence which support their historical existence. But what do we do with identities such as Matt, Mark, Luke and John? What do we do with Paul or Moses or Jesus? Sure we can assume their historical existence and add them as historical identities but the underlying data integrity would not be the same as that of the Roman emperors for example.
HYPOTHESES about the EVIDENCE
Evidence itself is mute. Historians must make hypotheses about the evidence. There's little or no escape from this. The way I see it is that theories about history (eg Christian origins) are entirely dependent on hypotheses and that as a result all theories must forever remain hypothetical. We may never know the historical "truth". Some hypotheses are going to be better explaining the data than other hypotheses but there is no guarantee for a "final solution".
ANCIENT HISTORY DATABASES
In a certain sense historians reconstruct an historical database from the assumptions and hypotheses which they themselves are obliged to make about the remaining evidence from antiquity. No such theory or such database is going to be free of data integrity issues.
I wrote an article which may be relevant here:
Ancient History: How Hypotheses about the evidence lead to Theoretical Conclusions and vice verse
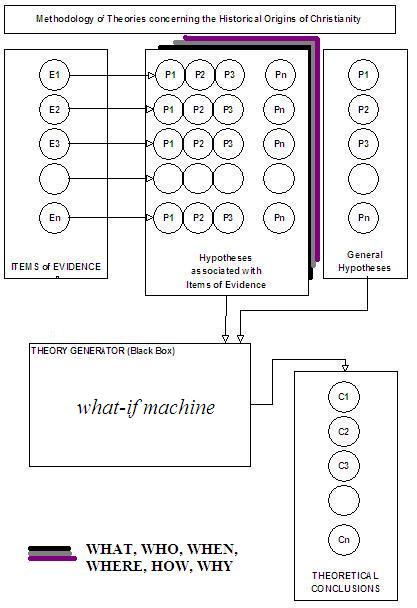
A process is identified to describe the methodology of historical theorizing in which evidence items are registered, one by one. Against each item of evidence hypotheses consistent of simple statements are then registered. These hypotheses are either formulated anew and/or recalled from old hypotheses previously formulated. All investigators are entitled to address any or all items of evidence, or add items of evidence to the register to be addressed. All investigators may select existing hypotheses directly related to each item of evidence, or formulate new hypotheses. General hypotheses may also be selected and/or formulated by all investigators. All these hypotheses, consistent of simple statements representative of the evidence and the conceptual framework of the investigator are input into a "Black Box" which is designated as a "Theory Generator", and theoretical conclusions are output.
This is essentially a "WHAT-IF" generator and its power is in its ability to perform massive iterations on changing sets of hypotheses:
The process is as follows:
(1)Evidence Items are registered
E1, E2, E3, ..., En
(2) For each evidence item
hypotheses are formulated;
P1, P2, P3, ..., Pn
(3) General hypotheses are added
GP1, GP2, GP3, ..., GPn
(4) All hypotheses become INPUT
to the "Black Box" of the Theory Generator
(5) Theoretical Conclusions are OUTPUT
C1, C2, C3, ..., Cn
There is a schematic diagram here:
ARTICLE LINK HERE:
http://mountainman.com.au/essenes/Ancie ... erator.htm
A process is identified to describe the methodology of historical theorizing in which evidence items are registered, one by one. Against each item of evidence hypotheses consistent of simple statements are then registered. These hypotheses are either formulated anew and/or recalled from old hypotheses previously formulated. All investigators are entitled to address any or all items of evidence, or add items of evidence to the register to be addressed. All investigators may select existing hypotheses directly related to each item of evidence, or formulate new hypotheses. General hypotheses may also be selected and/or formulated by all investigators. All these hypotheses, consistent of simple statements representative of the evidence and the conceptual framework of the investigator are input into a "Black Box" which is designated as a "Theory Generator", and theoretical conclusions are output.
This is essentially a "WHAT-IF" generator and its power is in its ability to perform massive iterations on changing sets of hypotheses:
The process is as follows:
(1)Evidence Items are registered
E1, E2, E3, ..., En
(2) For each evidence item
hypotheses are formulated;
P1, P2, P3, ..., Pn
(3) General hypotheses are added
GP1, GP2, GP3, ..., GPn
(4) All hypotheses become INPUT
to the "Black Box" of the Theory Generator
(5) Theoretical Conclusions are OUTPUT
C1, C2, C3, ..., Cn
There is a schematic diagram here:
ARTICLE LINK HERE:
http://mountainman.com.au/essenes/Ancie ... erator.htm